

In der "Deus Ex Machina? – KI-Tools im Test"-Reihe stellen wir euch verschiedene Tools vor, die mithilfe von Künstlicher Intelligenz Schreib‑, Design- und Rechercheprozesse vereinfachen sollen. Mehr zur "Deus Ex Machina?"-Reihe gibt es hier.
Im Überblick
Maschinell generierte Stimmen sind schon seit langem Teil des technologischen Alltags. Man kennt sie aus Warteschleifen, Callcentern, von Sprachassistenten und hat sofort diesen spezifischen, mechanisch klingenden Ton im Ohr, mit dem typischerweise ihre Ausgaben vertont werden. Wenn es nun um KI-generierte Stimmen geht, so liegt im ersten Moment der Schluss nahe, dass diese Stimmen ähnlich klingen würden. Das Tech-Startup ElevenLabs hat es sich zum Ziel gemacht, ein Tool zur Erstelltung KI-generierter Stimmen zu bauen, das möglichst realistisch klingende Stimmen erstellen soll, die von natürlichen Stimmen nicht zu unterscheiden sind. Bei ElevenLabs können User:innen Angebote für die unterschiedlichsten Arten KI-generierter Audios finden: Stimmklone, Synchronisationen, Vertonungen, Soundeffekte etc. Wir haben uns das Tool genauer angeschaut und es getestet.
ElevenLabs wurde 2022 von Ex Google-Engineer Piotr Dabkowski und Ex Palantir-Mitarbeiter Mati Staniszewski gegründet. Die Motivation dazu fanden die beiden Gründer eigenen Angaben nach in ihrer Jugend in Polen, in der sie immer wieder schlecht synchronisierte US-Filme sahen und sich über die Qualität der Synchronisation ärgerten. Mit ElevenLabs wollen sie Sprachbarrieren abbauen und Möglichkeiten schaffen, Inhalte weltweit und über Sprachgrenzen hinweg verständlich zu machen. In diversen Funding-Runden mit namenhaften Investor:innen (Nat Friedman, Daniel Gross, etc.) sammelte das Startup eine beachtliche Menge an Kapital und launchte 2023 bereits die ersten Produkte. Dem Unternehmen nach zählen beispielsweise das Telekommunikationsunternehmen cisco, der Computer- und Videospielentwickler Epic Games, sowie das Time Magazine mittlerweile zu den Anwender:innen von ElevenLabs.
Doch was genau kann das Tool – bzw. verspricht es zu können? ElevenLabs bietet seinen Anwender:innen ein breites Spektrum an KI-generierten Audiodienstleistungen, sowie auch eine Bild- und Videooption an. Herzstück des Angebots ist die sogenannte Text-to-Speech-Anwendung, welche vom Unternehmen 2023 erstmals veröffentlicht wurde. Hier können die Nutzer:innen geschriebene Texte eingeben, die das Tool dann in gesprochene Texte umwandelt. In unserem Test haben wir beispielsweise Ausschnitte eines Dialoges und das Skript eines Podcast eingegeben, welche uns das Tool dann als Audios ausgegeben hat. Dabei orientieren sich die Audioausgaben von ElevenLabs an natürlicher Sprache und klingen oft auch entsprechend realitätsnah. Spezifische Intonationen, Sprechpausen, emotionale Modulierungen, Atempausen und mehr, die gesprochene Sprache auszeichnen und lebendig machen, inkludiert das Tool in seine Ausgaben.
In unserem Praxistest haben wir uns auf die Audioangebote von ElevenLabs fokussiert und zunächst mit der V2-Version gearbeitet. Im Sommer 2025 veröffentlichte ElevenLabs eine aktualisierte, dritte Generation der Text-to-Spech Anwendung, zunächst als Alpha-Version. Seit Februar 2026 ist ElevenLabs V3 ohne Alpha-Status für die Nutzenden zugänglich. In unserem Test konnten wir ElevenLabs V2 und V3-Alpha intensiv testen. Die Beschreibung unserer Testerlebnisse bezieht sich also jeweils auf diese beiden Versionen.
Im Test der V2-Version konnten wir zunächst beobachten, dass ein längerer Eingabetext zu einer höheren Fehleranfälligkeit in den Audioausgaben führte. Kürzere Texte wurden durch das Tool der Eingabe getreuer und mit weniger Halluzinationen ausgegeben als längere Passagen. Gerade mit der Generierung “unsauberer” Elemente der gesprochenen Sprache, wie etwa dem Verschlucken von Silben, grammatikalisch falschen Wortendungen und mehr hatte das Tool wiederholt Schwierigkeiten, plausible Ergebnisse zu generieren. Über längere Passagen fiel zudem die sehr korrekte und oftmals überbetonte Aussprache auf, während die anfangs noch stark ausgeprägte Emotionalität und Modulierung nachließ. Diese “Übermodulierung” beeinflusste die Authentizität der Audioausgaben negativ. Über längere Zeiträume stellte sich ein uncanny valley-Effekt ein, der auch im Zusammenhang mit KI-generierten Inhalten zu beobachten ist. Im Test der 2025 veröffentlichten, aktualisierten V3-Version von ElevenLabs konnten wir feststellen, dass die Authentizität der generierten Stimmen aufgrund der besseren Steuerungsmöglichkeit bezüglich emotionaler Färbung der generierten Ausgaben nochmals deutlich höher war, jedoch aufgrund des Alpha-Status der Version die Anfälligkeit für Halluzinationen und Fehler ebenfalls gestiegen ist. Verfügbar ist diese Anwendung in 76 verschiedenen Sprachen.
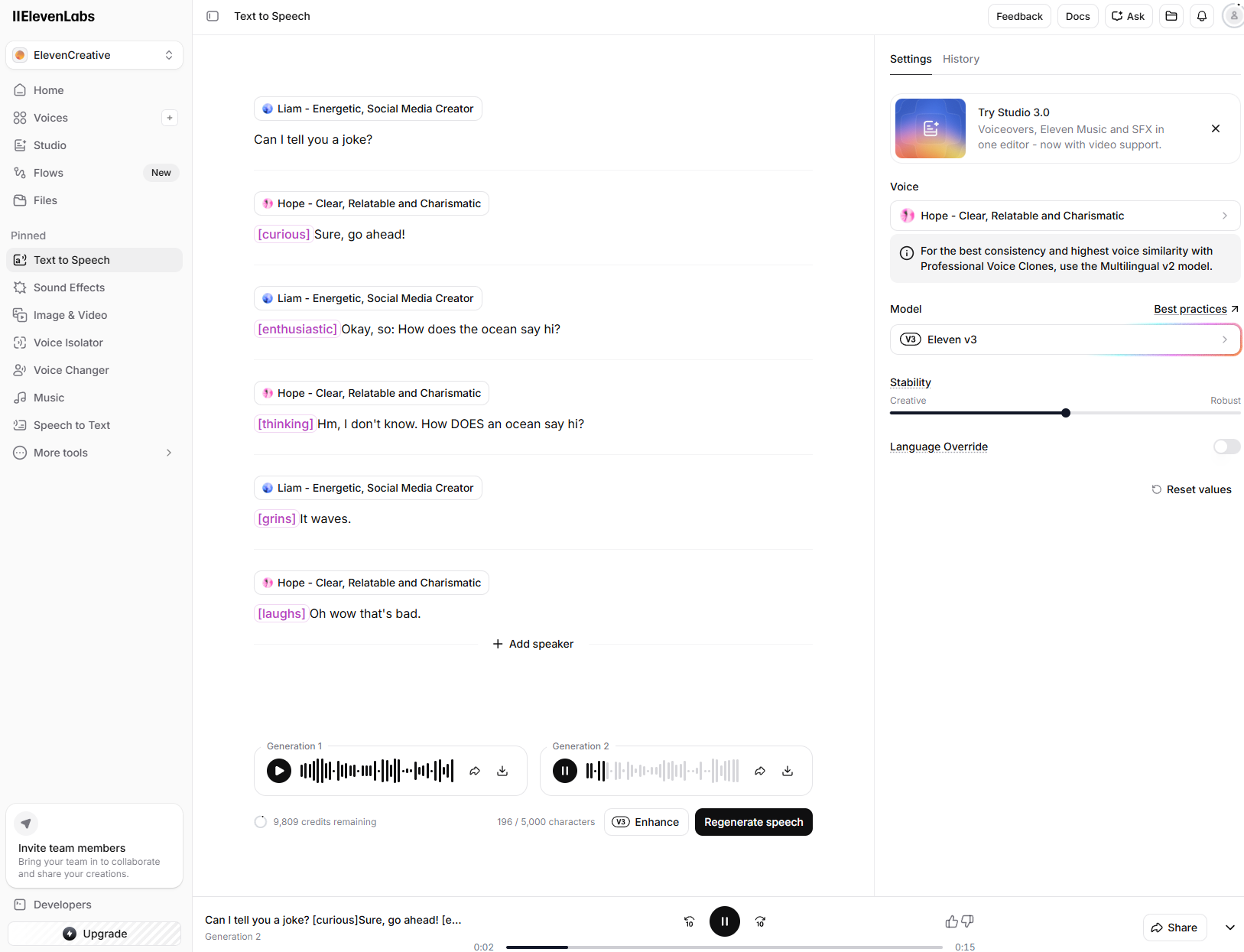
Bei der Auswahl der Stimmen, mit welchen die eingegebenen Texte vertont werden können, können die Nutzer:innen auf zwei Angebote zurückgreifen. Zum einen bietet ElevenLabs eine sogenannte Voice Library an, in der die Nutzer:innen aus hunderten, fertig trainierten Stimmen auswählen können. Diese sind in großen Kategorien wie Informative & Educational, Social Media, Characters & Animation, etc. sortiert, und differenzieren sich darunter noch nach verschiedenen Stimmungen, Intentionen und Charakteristika. So können Nutzende etwa eine motivierend-informative Stimme, eine gewitzte Social-Media-Stimme oder aber die Stimme eines Comic-Bösewichts auswählen, je nachdem welcher Charakter zu ihrem Text am besten passt.
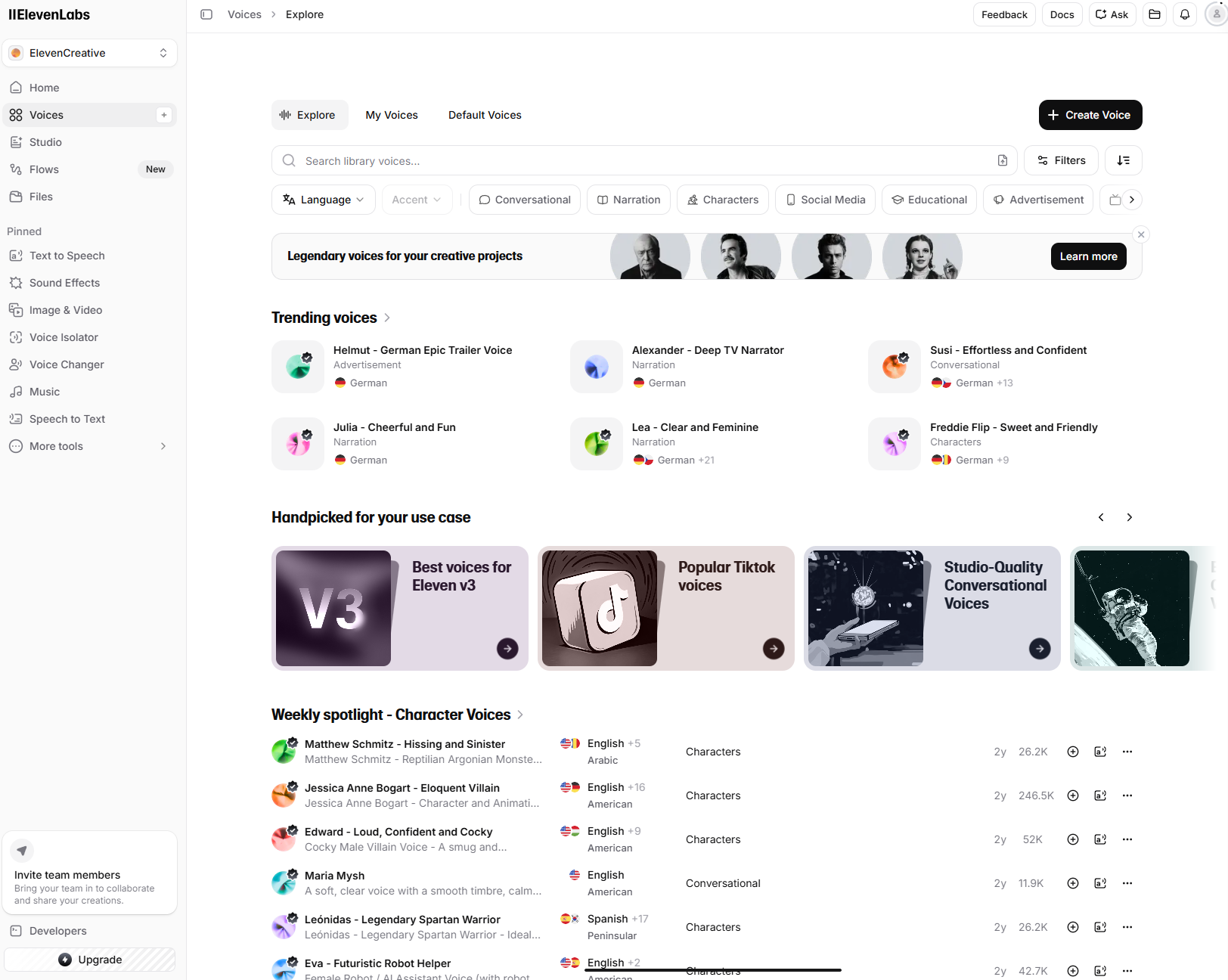
Zum anderen bietet ElevenLabs aber auch Voice Clones an. Nutzer:innen können einerseits über spezifische Eingaben zum Klang der Stimme (ähnlich den Charakteristika, die sich auch in der Voice Library wiederfinden) eine Stimme generieren lassen. Oder aber eine spezifische Stimme – beispielsweise die eigene – mittels KI nachbauen lassen und anschließend für die Audioausgabe verwenden. Möglich ist dies in Form von Instant- und Professional Voice Clones.
Die Instant Voice Clones können bereits auf Basis kürzerer Audiodateien (min. 10 Sekunden bis max. ca. 7 Minuten Länge) einer Stimme erstellt werden. Je besser die Audioqualität dieser Dateien, desto besser ist die Qualität des Klons. Der Instant Voice Clone übernimmt nun nicht nur Tonalität, Stimmlage und mehr, sondern auch Merkmale wie die Modulation oder Pausensetzung und wendet sie auf neue Audioausgaben an. Nutzer:innen haben dann noch die Möglichkeit, Eigenschaften des Stimmklons nachträglich zu bearbeiten und so beispielsweise durch Anpassung der Stabilität und Ausdrucksstärke einer Stimme ein möglichst authentisches und realitätsnahes Ergebnis zu erhalten. Jedoch haben diese nachträglichen Anpassungsmöglichkeiten ihre Grenzen und gehen mitunter zu Lasten anderer Stimmeigenschaften, wie etwa der Höhe oder Dynamik der Stimme.
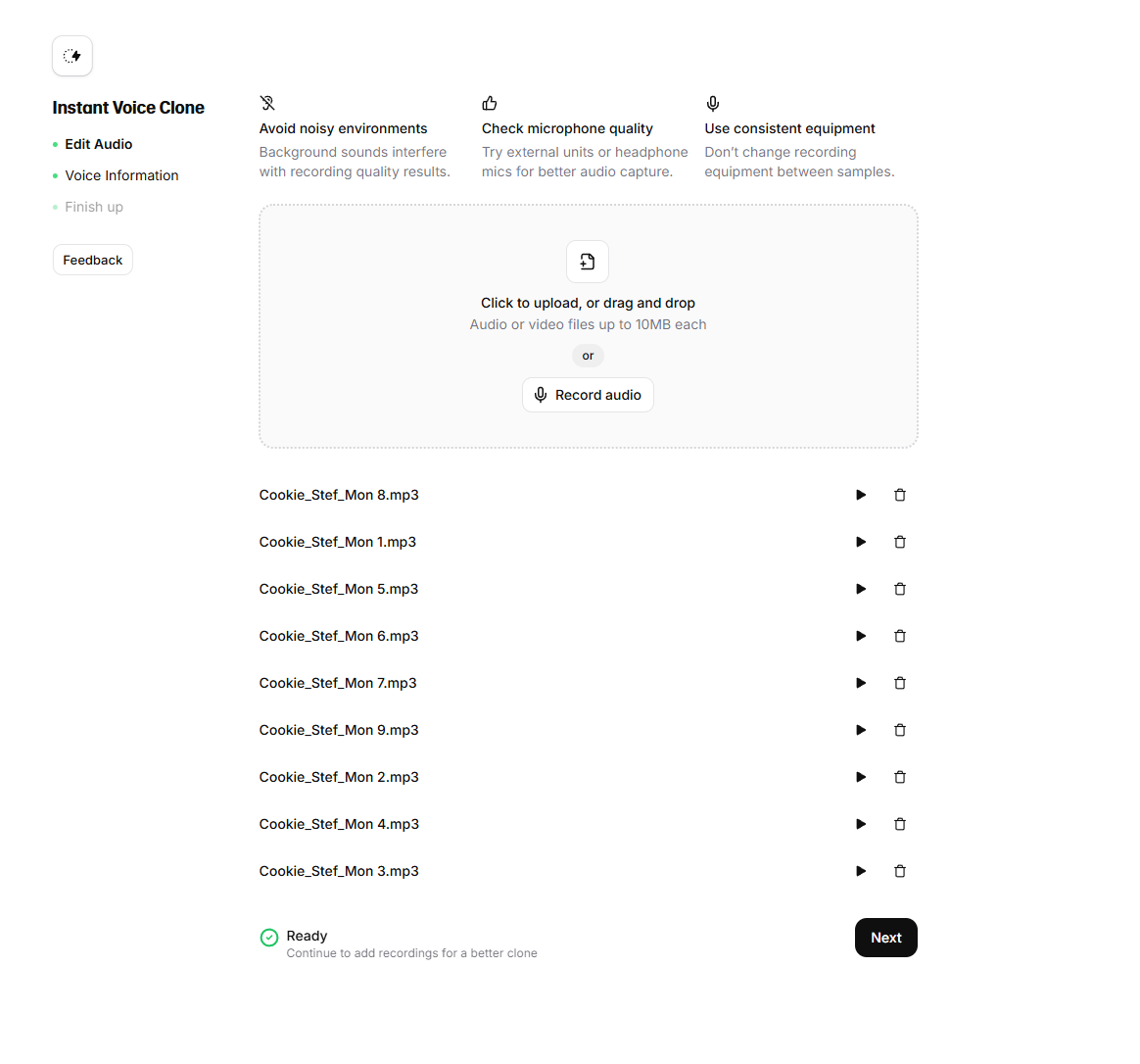
Für die Vertonung unseres Podcast-Texts haben wir zunächst zwei unterschiedliche Voice Clones mit dieser Methode erstellt und waren von der Qualität grundsätzlich überzeugt. Auffällig war jedoch, dass eine der beiden geklonten Stimmen dem Original ähnlicher war als die andere. Die Grundstabilität und Ausdrucksstärke einer menschlichen Stimme beeinflusst unserer Vermutung nach auch das Ergebnis des Voice Clones. Je konstanter die Originalstimme ist, also je weniger mit disruptiven Elementen und großer Varianz gesprochen wird, desto einfacher scheint es zu sein, für diese Stimme einen authentisch klingenden Stimmklon zu entwickeln. Schlechte Ergebnisse lieferte der Voice Clone in unserem Test bei sehr emotionalen Elementen mit hoher Devianz vom natürlichen Sprechduktus, wie etwa Lachen oder Singen. Hier klangen die Ergebnisse – auch nachdem Anpassungen vorgenommen und etwa explizit Lachen als Audioquelle hochgeladen wurde – nicht authentisch. Die V3-Version konnte hier abermals bessere Ergebnisse liefern. Gesang und Lachen konnten hier authentischer ausgegeben werden. Voraussetzung beim Gesang waren dafür jedoch neben dem expliziten Prompting von [sings] oder [singt] vor einem Textabschnitt das Einfügen spezifischer “Gesangsmarker” im Text, wie etwa „lalala“.
Die Professional Voice Clones konnten wir nicht testen. Hier sollen die Anwender:innen 30–180 Minuten Audiodateien zur Verfügung stellen und für das ElevenLabs-Team verifizieren, dass die zu klonende Stimme die eigene ist. Auf Grundlage dieser Daten erstellt das Tool in kurzer Zeit den Voice Clone, der dann zur Anwendung bereitsteht.
Für 29 Sprachen bietet ElevenLabs auch einen Voice Changer an. Hier können die Nutzenden selbst Audioaufnahmen einsprechen oder hochladen, welche das Tool dann in der Stimme eines Stimmklons oder einer Stimme aus der Voice Library ausgibt. In unserem Test zeigte sich diese Anwendung insbesondere für sehr emotionale Textabschnitte mit vielen Modulationen und Emphasen als nützlich, da diese von der eingesprochenen Stimme erhalten und lediglich in der Stimme des Klons wiedergegeben werden. Jedoch übernahm das Tool auch die Betonungen und Sprechweise der einsprechenden Stimme, wodurch die Ausgaben zwar stimmlich nach den Voice Clones klangen, andere Elemente des Sprechens wie etwa Duktus und Pausensetzung aber wiederum dem der einsprechenden Menschen entsprachen, was das Gesamtbild unstimmig machte. ElevenLabs bietet noch weitere Anwendungen an, die wir in unserem Test leider nicht ausprobieren konnten und deshalb an dieser Stelle nur grob vorstellen. Dazu zählt das Dubbing Studio, mit dem Inhalte in 29 Sprachen übersetzt werden können. Dafür müssen Nutzer:innen lediglich eine Audiodatei hochladen oder über einen Link auf einen Inhalt auf YouTube, X, TikTok, etc. verweisen und der Inhalt wird in die gewünschte Sprache übersetzt. Sprecher:in, Nebengeräusche, Videodateien, etc. bleiben erhalten, nur die Sprache ist angepasst. Laut eigenen Angaben funktioniert das Dubbing auch mit verschiedenen Sprecher:innen und innerhalb von kürzester Zeit.
Im Studio von ElevenLabs sollen die Nutzer:innen Hörbücher, Podcasts und Videos einfach produzieren können, indem das Tool dabei hilft, Video und Audio miteinander zu verbinden, passende Sprecher:innen zuzuteilen und ggf. notwenige Soundeffekte oder Untertitel hinzuzufügen. Auch wenn Nutzer:innen nur auf der Suche nach Soundeffekten sind, bietet ElevenLabs mit seiner Text-to-Sound-Effects-Funktion eine Möglichkeit. Hier können auf Basis von Textprompts, wie etwa „Sanftes Wellenrauschen mit Möwengeschrei und einem Schiffshorn im Hintergrund“, Soundeffekte ausgegeben und in Audioprojekte integriert werden. Ähnlich wie bei der Voice Library bietet ElevenLabs seinen Nutzer:innen auch bereits eine Sammlung vorgefertigter Soundeffekte unterschiedlichster Kategorien an.
Daneben können Anwender:innen über die Speech-to-Text-Funktion des Tools auch Transkriptionen mit ElevenLabs vornehmen und so Podcasts, Interviews, etc. in Texte umwandeln. Das ist in 99 verschiedenen Sprachen möglich.
Mit seiner Agents-Plattform hält ElevenLabs ein Angebot für Unternehmen und Anwender:innen bereit, die auf der Suche nach KI-basierten Lösungen für den Kundensupport sind. Auf der Agents-Plattform können eigene KI-Agenten erstellt und für den Einsatz im Kundensupport oder andere Anwendungsbereiche trainiert werden.
Zur Nutzung des Tools reicht eine Anmeldung via E‑Mail. Dann bieten sich beschränkte Möglichkeiten der kostenfreien Nutzung des Tools. Größeren Spielraum haben Anwender:innen mit einem der angebotenen Abo-Modelle, die von fünf Dollar pro Monat bis hin zu individuellen Preisen für Unternehmen rangieren. Je nach Modell stehen den Nutzer:innen mehr Tokens zur Verfügung, also mehr Datenkapazitäten, ebenso sind manche der Angebote erst ab spezifischen Abos inklusive.
Wie gut die Ergebnisse von ElevenLabs sind, variiert darüber hinaus von Sprache zu Sprache. Für häufiger gesprochene Sprachen, wie Englisch, Deutsch oder Spanisch klingen die Ausgaben besser als für seltener gesprochene Sprachen, was vermutlich an den Trainingsdaten liegt, mit denen das Tool trainiert wurde und die in ihrer Häufigkeit variieren, je nachdem wie viele Sprecher:innen dieser Sprache es weltweit gibt.
Die KI hinter der Anwendung
Wie bei den meisten KI-Tools ist auch bei ElevenLabs eine genaue Beschreibung der zugrundeliegenden KI-Technologie nicht möglich. ElevenLabs hält die Angaben zu ihrem KI-System sehr vage. Was mit Sicherheit gesagt werden kann ist, dass ElevenLabs mit eigenen, komplexen Deep-Learning-Modellen arbeitet. Diese sind darauf trainiert zu erkennen, wie Menschen natürlicherweise sprechen und dies zu reproduzieren. Dabei werden Merkmale wie der Kontext einer Aussage beispielsweise mit der Tonalität, Emotionalität und Lautstärke der gesprochenen Sequenz in Verbindung gebracht, um individuelle Muster in Betonung, Sprachmelodie, Sprachfluss und mehr zu erkennen und sie dann maschinell generieren zu können. Dafür verwendet ElevenLabs verschiedene Layer an Neuronalen Netzwerken, sowie Generative Adversarial Networks (GANs) und eine spezifische Transformer-Architektur.
Das rhetorische Potenzial des Tools
ElevenLabs ist auf gesprochene Sprache spezialisiert, weshalb aus rhetorischer Perspektive betrachtet die Anwendungsmöglichkeiten primär in den Bereich der so genannten actio, also des praktischen Redeauftritts oder anders gesprochen, des rhetorisch-kommunikativen Aktes in der Praxis, fallen. ElevenLabs hat das Potenzial, die Praxis des kommunikativen Aktes zu erleichtern oder in bestimmten Fällen erst zu ermöglichen.
Eine Erleichterung kann dabei etwa Zeitersparnis sein. Statt beispielsweise einen Podcast oder ein Video selbst einzusprechen, kann mit ElevenLabs dieses Kommunikat generiert werden. Dabei kann außerdem eine passende Stimme strategisch ausgewählt werden, um eine spezifische, intendierte Wirkung zu erreichen. Außerdem können durch die Mehrsprachigkeit und Dubbing-Funktion des Tools auch Zielgruppen und sprachliche Räume erschlossen werden, die eigentlich verschlossen sind. Denn Überzeugungsarbeit läuft einigen rhetorischen Theoretiker:innen nach, wie beispielsweise Kenneth Burke, über Identifikation ab. Erreicht eine Person also ein Text in ihrer Muttersprache statt beispielsweise auf Englisch, so liegt das identifikatorische Potenzial und damit auch das Überzeugungspotenzial schon einmal näher. Jedoch kann ElevenLabs auf textueller Ebene keine Veränderungen vornehmen und so etwa Formulierungen, Begriffe oder Humor nicht auf spezifische Sprach- und Kulturräume anpassen, was das persuasive Potenzial nochmals erhöhen würde. Rhetorisch gesehen kann ElevenLabs neue mediale Räume eröffnen und die Anwender:innen so befähigen, ihre Inhalte weiter zu distribuieren – zum Beispiel von einem geschriebenen Text in einen Podcast. Dazu lassen sich auch multimodale Effekte durch das Tool leichter erstellen. Jedoch müssen auch hier medienspezifische Anforderungen und Veränderungen durch die Anwender:innen bedacht werden, um beispielsweise ein Video für TikTok passend zu gestalten.
Anwendung in der Wissenschaftskommunikation
Daran anschließend lässt sich für die Anwendung in der Wissenschaftskommunikation ein ähnliches Bild zeichnen: ElevenLabs kann dabei helfen, Inhalte aufzubereiten, um sie an ein größeres und diverseres Publikum zu distribuieren. Sprachräume stellen so keine schwer überwindbaren Grenzen mehr da. Insbesondere für Mitglieder einer kleineren Sprachcommunity kann das die Möglichkeit bedeuten, aktiver in den wissenschaftlichen Diskurs einzutreten und ihn mitzuprägen.
Jedoch muss immer mit der Anfälligkeit des Systems für Fehler, Halluzinationen und mehr gerechnet werden. Wird ein Text in eine Sprache übersetzt, derer die Anwender:innen selbst nicht mächtig sind, können diese das ausgegebene Ergebnis nicht gegenprüfen. Dadurch muss mit der Möglichkeit gerechnet werden, dass Informationen falsch wiedergegeben werden, was im Falle von Wissenschaftskommunikation mitunter schwerwiegende Folgen haben kann. Da ElevenLabs gerade für Sprachen, die weltweit seltener gesprochen werden, auch fehlerhaftere Ergebnisse generiert, muss dieses Risiko von Kommunikator:innen sorgfältig abgewogen werden.
Mit ElevenLabs müssten Wissenschaftskommunikator:innen ihre Inhalte nicht mehr selbst einsprechen und könnten Aufgaben wie Schnitt, Zusammenführen von Audio und Video, Untertitelerstellung, etc. mit Unterstützung des Tools einfacher und schneller erledigen. Dadurch ergibt sich eine Zeitersparnis, die beispielsweise für eine noch tiefergehende Recherche verwendet werden kann. Die Unterstützung des Tools könnte wissenschaftskommunikativ tätigen Anwender:innen aber auch ermöglichen, schneller auf öffentliche Bedürfnisse nach Wissenschaftskommunikation im Diskurs zu reagieren und damit der Ausbreitung von etwa Fehlinformationen, Angst oder ähnlichen diskursiven Phänomenen zeitnah entgegenwirken.
Wrap Up
Mit ElevenLabs bekommen Anwender:innen ein vieseitiges Tool, das viele Bedarfe der KI-generierten Sound- und Stimmproduktion abdeckt. Die Produkte des Unternehmens können dabei helfen, Audioproduktion zu erleichtern und Sprachgrenzen zu überwinden. Jedoch ist das Tool nicht frei von Fehleranfälligkeit und lässt mitunter an Authentizität zu wünschen übrig. Auch bei der Übersetzung in weniger verbreitete Sprachen stellt die Fehleranfälligkeit des Tools ein Problem dar. Zudem bleibt das Risiko, dass Stimmen als biometrische Daten leichter dem Missbrauch ausgesetzt sind. Hier fehlt es insgesamt noch an Reglementierungen.


